> For the complete documentation index, see [llms.txt](https://www.mlcompendium.com/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://www.mlcompendium.com/foundation-knowledge/information-theory.md).
# Information Theory
### **ENTROPY / INFORMATION GAIN**
1. [**Shannon entropy in python, basically entropy(value counts)**](https://www.kite.com/python/answers/how-to-calculate-shannon-entropy-in-python)
2. [**Mastery on plogp entropy function**](https://machinelearningmastery.com/what-is-information-entropy/)
3. [**Entropy functions**](https://gist.github.com/jaradc/eeddf20932c0347928d0da5a09298147)
### Tools
1. [EntroPy](https://raphaelvallat.com/entropy/build/html/index.html#) / [AntroPy](https://raphaelvallat.com/antropy/build/html/index.html) \[[Git](https://github.com/raphaelvallat/antropy)]
2. [PyInform](https://github.com/ELIFE-ASU/PyInform) \[[Docs](https://elife-asu.github.io/PyInform/index.html)]- PyInform is a python library of information-theoretic measures for time series data. PyInform is backed by the [Inform](https://github.com/elife-asu/inform) C library.
3. [PyEntropy](https://github.com/nikdon/pyEntropy)
### Tutorials
[**Great tutorial on all of these topics**](https://www.bogotobogo.com/python/scikit-learn/scikt_machine_learning_Decision_Tree_Learning_Informatioin_Gain_IG_Impurity_Entropy_Gini_Classification_Error.php)**\*\*\***
[**Entropy**](https://www.techleer.com/articles/496-a-short-introduction-to-entropy-cross-entropy-and-kl-divergence-aurelien-geron/) **- lack of order or lack of predictability (**[**excellent slide lecture by Aurelien Geron**](https://www.youtube.com/watch?time_continue=3\&v=ErfnhcEV1O8)**)**

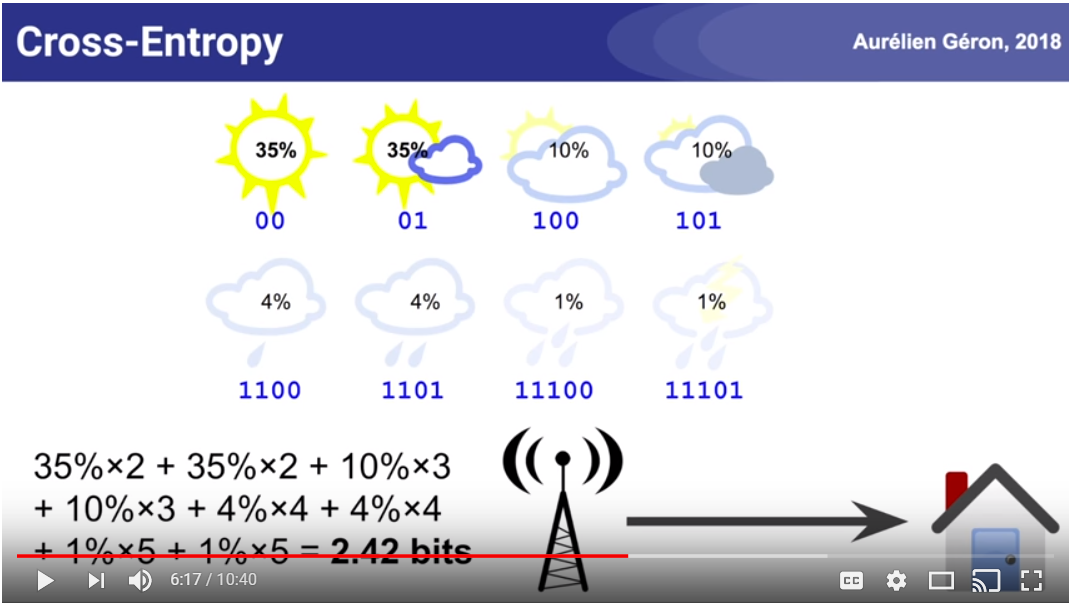
**Cross entropy will be equal to entropy if the probability distributions of p (true) and q(predicted) are the same. However, if cross entropy is bigger (known as relative\_entropy or kullback leibler divergence)**


**In this example we want the cross entropy loss to be zero, i.e., when we have a one hot vector and a predicted vector which are identical, i.e., 100% in the same class for predicted and true, we get 0. In all other cases we get some number that gets larger if the predicted class probability is lower than zero as seen here:**
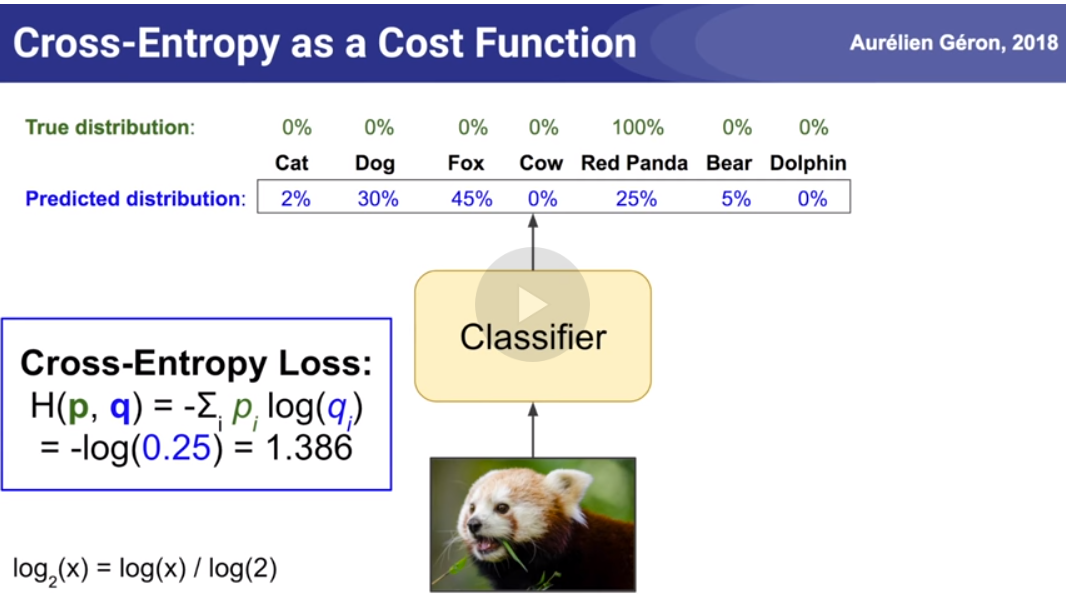
**Formula for 2 classes:**
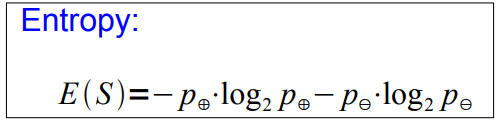
**NOTE: Entropy can be generalized as a formula for N > 2 classes:**
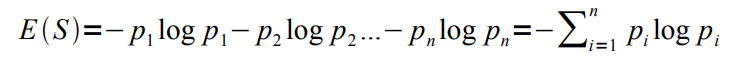
**(We want to grow a simple tree)** [**awesome pdf tutorial**](http://www.ke.tu-darmstadt.de/lehre/archiv/ws0809/mldm/dt.pdf)**→ a good attribute prefers attributes that split the data so that each successor node is as pure as possible**
* **i.e., the distribution of examples in each node is so that it mostly contains examples of a single class**
* **In other words: We want a measure that prefers attributes that have a high degree of „order“:**
* **Maximum order: All examples are of the same class**
* **Minimum order: All classes are equally likely → Entropy is a measure for (un-)orderedness Another interpretation:**
* **Entropy is the amount of information that is contained**
* **all examples of the same class → no information**
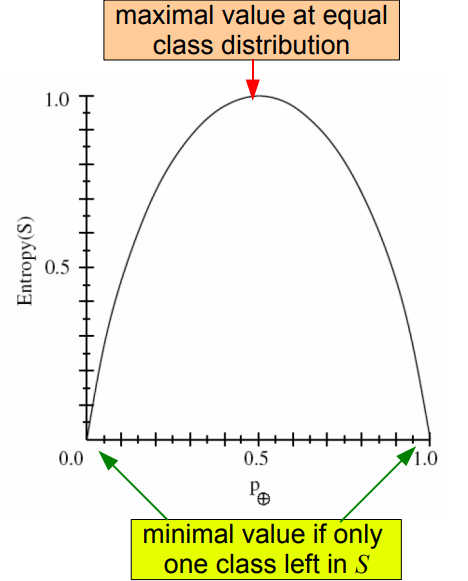
**Entropy is the amount of unorderedness in the class distribution of S**
**IMAGE above:**
* **Maximal value when the equal class distribution**
* **Minimal value when only one class is in S**
**So basically if we have the outlook attribute and it has 3 categories, we calculate the entropy for E(feature=category) for all 3.**

**INFORMATION: The I(S,A) formula below.**
**What we actually want is the average entropy of the entire split, that corresponds to an entire attribute, i.e., OUTLOOK (sunny & overcast & rainy)**

**Information Gain: is actually what we gain by subtracting information from the entropy.**
**In other words we find the attributes that maximizes that difference, in other other words, the attribute that reduces the unorderness / lack of order / lack of predictability.**
**The BIGGER GAIN is selected.**

**There are some properties to Entropy that influence INFO GAIN (?):**

**There are some disadvantages with INFO GAIN, done use it when an attribute has many number values, such as “day” (date wise) 05/07, 06/07, 07/07..31/07 etc.**
**Information gain is biased towards choosing attributes with a large number of values and causes:**
* **Overfitting**
* **fragmentation**

**We measure Intrinsic information of an attribute, i.e., Attributes with higher intrinsic information are less useful.**
**We define Gain Ratio as info-gain with less bias toward multi value attributes, ie., “days”**
**NOTE: Day attribute would still win with the Gain Ratio, Nevertheless: Gain ratio is more reliable than Information Gain**

**Therefore, we define the alternative, which is the GINI INDEX. It measures impurity, we define the average Gini, and the Gini Gain.**
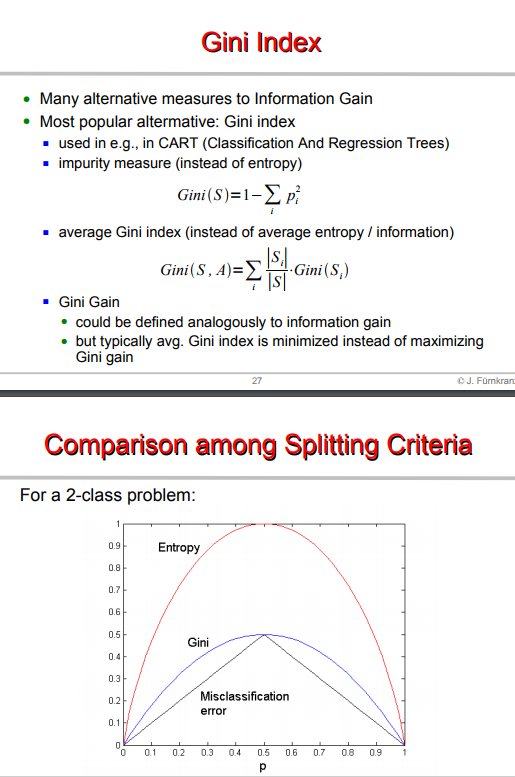
[**FINALLY, further reading about decision trees and examples of INFOGAIN and GINI here.**](http://www.ke.tu-darmstadt.de/lehre/archiv/ws0809/mldm/dt.pdf)
[**Variational bounds on mutual informati**](https://arxiv.org/abs/1905.06922v1)**on**
### **CROSS ENTROPY, RELATIVE ENT, KL-D, JS-D, SOFT MAX**
1. [A really good explanation on all of them](https://www.countbayesie.com/blog/2017/5/9/kullback-leibler-divergence-explained)
2. [Another good one on all of them](https://gombru.github.io/2018/05/23/cross_entropy_loss/)
3. [mastery on a gentle intro to CE](https://machinelearningmastery.com/cross-entropy-for-machine-learning/)
4. [Mastery on entropy](https://machinelearningmastery.com/divergence-between-probability-distributions/), kullback leibler divergence (asymmetry), jensen-shannon divergence (symmetry) (has code)
5. [Entropy, mutual information and KL Divergence by AurelienGeron](https://www.techleer.com/articles/496-a-short-introduction-to-entropy-cross-entropy-and-kl-divergence-aurelien-geron/)
6. [Gensim on divergence](https://radimrehurek.com/gensim/auto_examples/tutorials/run_distance_metrics.html#sphx-glr-auto-examples-tutorials-run-distance-metrics-py) metrics such as KL jaccard etc, pros and cons, lda is a mess on small data.
7. [Advise on KLD](https://datascience.stackexchange.com/questions/9262/calculating-kl-divergence-in-python)ivergence
8. [Neural machine translation using pytorch and CE](https://towardsdatascience.com/neural-machine-translation-15ecf6b0b)
### SOF**TMAX**
1. [**Understanding softmax**](https://medium.com/data-science-bootcamp/understand-the-softmax-function-in-minutes-f3a59641e86d)
2. [**Softmax and negative likelihood (NLL)**](https://ljvmiranda921.github.io/notebook/2017/08/13/softmax-and-the-negative-log-likelihood/)
3. [**Softmax vs cross entropy**](https://www.quora.com/Is-the-softmax-loss-the-same-as-the-cross-entropy-loss#) **- Softmax loss and cross-entropy loss terms are used interchangeably in industry. Technically, there is no term as such Softmax loss. people use the term "softmax loss" when referring to "cross-entropy loss". The softmax classifier is a linear classifier that uses the cross-entropy loss function. In other words, the gradient of the above function tells a softmax classifier how exactly to update its weights using some optimization like** [**gradient descent**](https://en.wikipedia.org/wiki/Gradient_descent)**.**
**The softmax() part simply normalises your network predictions so that they can be interpreted as probabilities. Once your network is predicting a probability distribution over labels for each input, the log loss is equivalent to the cross entropy between the true label distribution and the network predictions. As the name suggests, softmax function is a “soft” version of max function. Instead of selecting one maximum value, it breaks the whole (1) with maximal element getting the largest portion of the distribution, but other smaller elements getting some of it as well.**
**This property of softmax function that it outputs a probability distribution makes it suitable for probabilistic interpretation in classification tasks.**
**Cross entropy indicates the distance between what the model believes the output distribution should be, and what the original distribution is. Cross entropy measure is a widely used alternative of squared error. It is used when node activations can be understood as representing the probability that each hypothesis might be true, i.e. when the output is a probability distribution. Thus it is used as a loss function in neural networks which have softmax activations in the output layer.**
### **TIME SERIES ENTROPY**
1. [**entroPY**](https://raphaelvallat.com/entropy/build/html/index.html) **- EntroPy is a Python 3 package providing several time-efficient algorithms for computing the complexity of one-dimensional time-series. It can be used for example to extract features from EEG signals.**
[**Approximate entropy paper**\
](https://journals.physiology.org/doi/pdf/10.1152/ajpheart.2000.278.6.H2039)
**print(perm\_entropy(x, order=3, normalize=True)) # Permutation entropy**
**print(spectral\_entropy(x, 100, method='welch', normalize=True)) # Spectral entropy**
**print(svd\_entropy(x, order=3, delay=1, normalize=True)) # Singular value decomposition entropy**
**print(app\_entropy(x, order=2, metric='chebyshev')) # Approximate entropy**
**print(sample\_entropy(x, order=2, metric='chebyshev')) # Sample entropy**
**print(lziv\_complexity('01111000011001', normalize=True)) # Lempel-Ziv complexity**
1. [**PyInform**](https://elife-asu.github.io/PyInform/index.html)
### **Complement Objective Training**
1. **Article by** [**LightTag**](https://www.lighttag.io/blog/complement-objective-training-with-pytorch-lightning/)**,** [**paper**](https://arxiv.org/pdf/1903.01182.pdf) **-**
**COT is a technique to effectively provide explicit negative feedback to our model. The technique gives us non-zero gradients with respect to incorrect classes, which are used to update the model's parameters.**
**COT doesn't replace cross-entropy. It's used as a second training step as follows: We run cross-entropy, and then we do a COT step. We minimize the cross-entropy between our target distribution. That's equivalent to maximizing the likelihood of the correct class. During the COT step, we maximize the entropy of the complement distribution. We pretend that the correct class isn't an option and make the remaining classes equally likely.**
**But, since the true class is an option, and we're training for it explicitly, maximizing the true classes probability and pushing the remaining classes to be equally likely is actually pushing their probabilities to 0 explicitly, which provides explicit gradients to propagate through our model.**
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter, and the optional `goal` query parameter:
```
GET https://www.mlcompendium.com/foundation-knowledge/information-theory.md?ask=&goal=
```
`ask` is the immediate question: it should be specific, self-contained, and written in natural language.
`goal` is optional and describes the broader end goal you are ultimately trying to accomplish on behalf of the user. GitBook uses it to tailor the answer towards what is most useful for that goal.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.