> For the complete documentation index, see [llms.txt](https://www.mlcompendium.com/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://www.mlcompendium.com/machine-learning/classic-machine-learning.md).
# Probabilistic, Regression
### **PROBABILISTIC ALGORITHMS**
#### **NAIVE BAYES**
1. [**Vidhya on NB**](https://towardsdatascience.com/my-secret-sauce-to-be-in-top-2-of-a-kaggle-competition-57cff0677d3c?fbclid=IwAR3Iei5OmwswIMbbqcz2dNr5rLsWS-iuuaAuOjmhCELTTEBTPmSM85mTw7U)
2. [**Baysian tree**](https://github.com/UBS-IB/bayesian_tree)
3. [**NB, GNB, multi nominal NB**](https://jakevdp.github.io/PythonDataScienceHandbook/05.05-naive-bayes.html)
#### **BAYES, BAYESIAN BELIEF NETWORKS**
1. [**Mastery on bayes theorem**](https://machinelearningmastery.com/bayes-theorem-for-machine-learning/?fbclid=IwAR3txPR1zRLXhmArXsGZFSphhnXyLEamLyyqbAK8zBBSZ7TM3e6b3c3U49E)
2. [**Introduction To BBS**](https://codesachin.wordpress.com/2017/03/10/an-introduction-to-bayesian-belief-networks/) **- a very good blog post**
3. **A** [**complementing SLIDE presentation**](https://www.slideshare.net/GiladBarkan/bayesian-belief-networks-for-dummies) **that shows how to build the network’s tables**
4. **A** [**very nice presentation**](http://chem-eng.utoronto.ca/~datamining/Presentations/Bayesian_Belief_Network.pdf) **regarding BBS**
5.
6. [**Maximum Likelihood**](http://mathworld.wolfram.com/MaximumLikelihood.html) **(log likelihood) - proofs for bernoulli, normal, poisson.**
7. [**Another example**](https://codesachin.wordpress.com/2017/03/10/an-introduction-to-bayesian-belief-networks/)
#### **MARKOV MODELS**
**Random vs Stochastic (**[**here**](https://math.stackexchange.com/questions/114373/whats-the-difference-between-stochastic-and-random) **and** [**here**](https://math.stackexchange.com/questions/569951/what-is-the-difference-between-a-random-vector-and-a-stochastic-process)**):**
* **A variable is 'random'.**
* **A process is 'stochastic'.**
**Apart from this difference the two words are synonyms**
**In other words:**
* **A random vector is a generalization of a single random variables to many.**
* **A stochastic process is a sequence of random variables, or a sequence of random vectors (and then you have a vector-stochastic process).**
**(**[**What is a Markov Model?)**](http://cecas.clemson.edu/~ahoover/ece854/refs/Ramos-Intro-HMM.pdf) **A Markov Model is a stochastic(random) model which models temporal or sequential data, i.e., data that are ordered.**
* **It provides a way to model the dependencies of current information (e.g. weather) with previous information.**
* **It is composed of states, transition scheme between states, and emission of outputs (discrete or continuous).**
* **Several goals can be accomplished by using Markov models:**
* **Learn statistics of sequential data.**
* **Do prediction or estimation.**
* **Recognize patterns.**
**(**[**sunny cloudy explanation**](http://techeffigytutorials.blogspot.co.il/2015/01/markov-chains-explained.html)**) Markov Chains is a probabilistic process, that relies on the current state to predict the next state.**
* **to be effective the current state has to be dependent on the previous state in some way**
* **if it looks cloudy outside, the next state we expect is rain.**
* **If the rain starts to subside into cloudiness, the next state will most likely be sunny.**
* **Not every process has the Markov Property, such as the Lottery, this weeks winning numbers have no dependence to the previous weeks winning numbers.**
1. **They show how to build an order 1 markov table of probabilities, predicting the next state given the current.**
2. **Then it shows the state diagram built from this table.**
3. **Then how to build a transition matrix from the 3 states, i.e., from the probabilities in the table**
4. **Then how to calculate the next state using the “current state vector” doing vec\*matrix multiplications.**
5. **Then it talks about the setting always into the rain prediction, and the solution is using two last states in a bigger table of order 2. He is not really telling us why the probabilities don't change if we add more states, it stays the same as in order 1, just repeating.**
#### **MARKOV MODELS / HIDDEN MARKOV MODEL**
**HMM tutorials**
1. **HMM tutorial**
1. **Part** [**1**](http://gekkoquant.com/2014/05/18/hidden-markov-models-model-description-part-1-of-4/)**,** [**2**](http://gekkoquant.com/2014/05/26/hidden-markov-models-forward-viterbi-algorithm-part-2-of-4/)**,** [**3**](http://gekkoquant.com/2014/09/07/hidden-markov-models-examples-in-r-part-3-of-4/)**,** [**4**](http://gekkoquant.com/2015/02/01/hidden-markov-models-trend-following-sharpe-ratio-3-1-part-4-of-4/)
2. **Medium**
1. [**Intro to HMM**](https://towardsdatascience.com/introduction-to-hidden-markov-models-cd2c93e6b781) **/ MM**
2. [**Paper like example**](https://medium.com/@kangeugine/hidden-markov-model-7681c22f5b9)
3. [**HMM with sklearn and networkx**](http://www.blackarbs.com/blog/introduction-hidden-markov-models-python-networkx-sklearn/2/9/2017)
**HMM variants**
1. [**Stack exchange on hmm**](https://datascience.stackexchange.com/questions/8460/python-library-to-implement-hidden-markov-models)
2. [**HMM LEARN**](https://github.com/hmmlearn/hmmlearn) **(sklearn, still being developed)**
3. [**Pomegranate**](https://pomegranate.readthedocs.io/en/latest/) **(this is good)**
1. **General mixture models**
2. **Hmm**
3. **Basyes classifiers and naive bayes**
4. **Markov changes**
5. **Bayesian networks**
6. **Markov networks**
7. **Factor graphs**
4. [**GHMM with python wrappers**](http://ghmm.org/)**,**
5. [**Hmms**](https://github.com/lopatovsky/HMMs) **(old)**
**HMM (**[**what is? And why HIDDEN?)**](https://youtu.be/jY2E6ExLxaw?t=27m38s) **- the idea is that there are things that you CAN OBSERVE and there are things that you CAN'T OBSERVE. From the things you OBSERVE you want to INFER the things you CAN'T OBSERVE (HIDDEN). I.e., you play against someone else in a game, you don't see their choice of action, but you see the result.**
1. **Python** [**code**](https://github.com/hmmlearn/hmmlearn)**, previously part of** [**sklearn** ](http://scikit-learn.sourceforge.net/stable/modules/hmm.html)
2. **Python** [**seqLearn**](http://larsmans.github.io/seqlearn/reference.html) **- supervised multinomial HMM**
**This youtube video** [**part1**](https://www.youtube.com/watch?v=TPRoLreU9lA) **- explains about the hidden markov model. It shows the visual representation of the model and how we go from that the formula:** 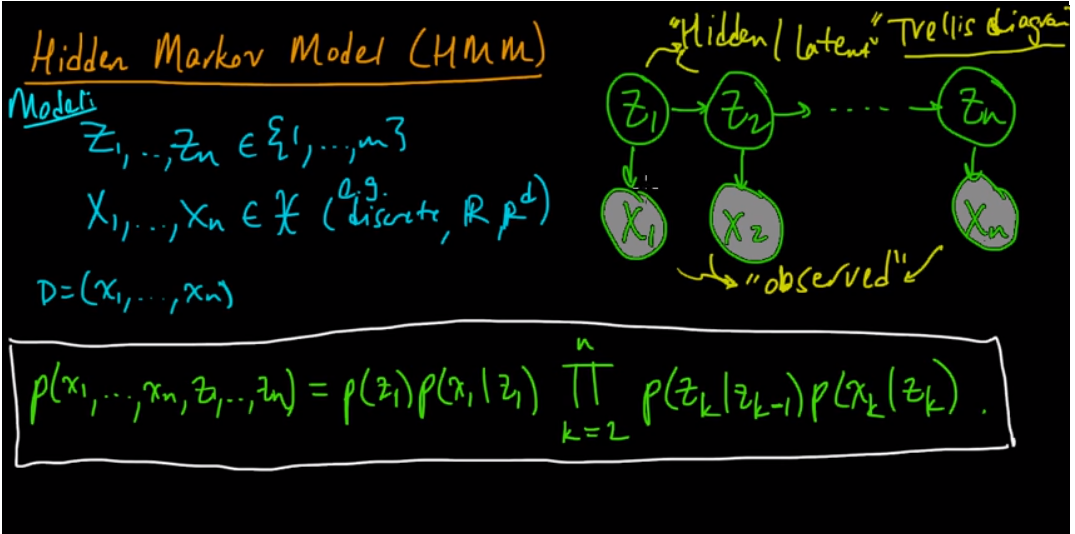
**It breaks down the formula to:**
* **transition probability formula - the probability of going from Zk to Zk+1**
* **emission probability formula - the probability of going from Zk to Xk**
* **(Pi) Initial distribution - the probability of Z1=i for i=1..m**

**In** [**part2**](https://www.youtube.com/watch?v=M_IIW0VYMEA) **of the video:**
**\*** [**HMM in weka, with github, working on 7.3, not on 9.1**](http://www.doc.gold.ac.uk/~mas02mg/software/hmmweka/index.html)
1. **Probably the simplest explanation of Markov Models and HMM as a “game” -** [**link**](http://www.fejes.ca/EasyHMM.html)
2. **This** [**video**](https://www.youtube.com/watch?v=jY2E6ExLxaw) **explains that building blocks of the needed knowledge in HMM, starting probabilities P0, transitions and emissions (state probabilities)**
3. **This** [**post**](https://www.quora.com/What-is-a-simple-explanation-of-the-Hidden-Markov-Model-algorithm)**, explains HMM and ties our understanding.**
[**A cute explanation on quora**](https://www.quora.com/What-is-a-simple-explanation-of-the-Hidden-Markov-Model-algorithm)**:**
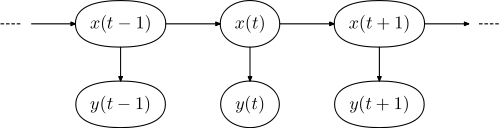
**This is the iconic image of a Hidden Markov Model. There is some state (x) that changes with time (markov). And you want to estimate or track it. Unfortunately, you cannot directly observe this state (hidden). That's the hidden part. But, you can observe something correlated with the state (y).**
**OBSERVED DATA -> INFER -> what you CANT OBSERVE (HIDDEN).**
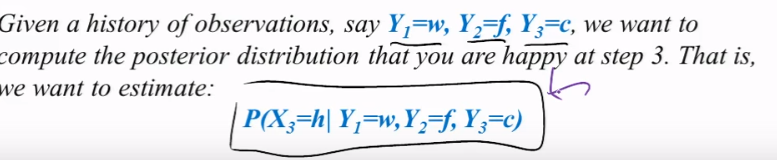
**Considering this model:**
* **where P(X0) is the initial state for happy or sad**
* **Where P(Xt | X t-1) is the transition model from time-1 to time**
* **Where P(Yt | Xt) is the observation model for happy and sad (X) in 4 situations (w, sad, crying, facebook)**
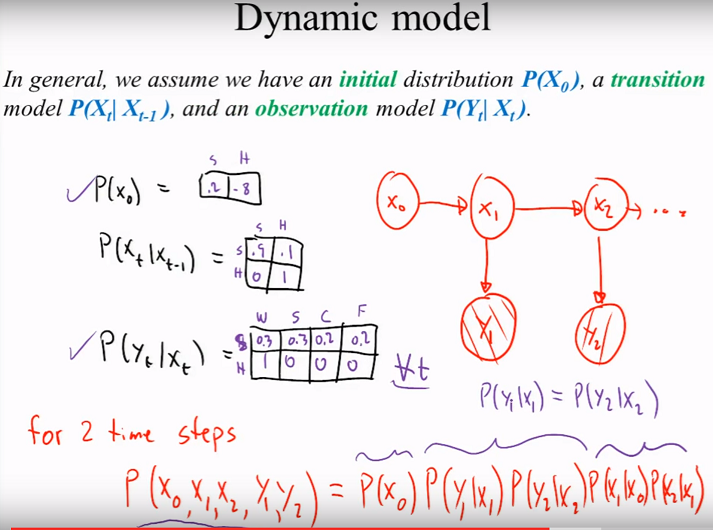
#### **INPUT OUTPUT HMM (IOHMM)**
1. [**Incomplete python code**](https://github.com/Mogeng/IOHMM) **for unsupervised / semi-supervised / supervised IOHMM - training is there, prediction is missing.**
2. [**Machine learning - a probabilistic approach, david barber.**](https://pdfs.semanticscholar.org/a632/9a41ee67fae978ccac1e37370f074497a4fe.pdf)
#### **CONDITIONAL RANDOM FIELDS (CRF)**
1. [**Make sense intro to CRF, comparison against HMM** ](https://medium.com/ml2vec/overview-of-conditional-random-fields-68a2a20fa541)
2. [**HMM, CRF, MEMM**](https://medium.com/@Alibaba_Cloud/hmm-memm-and-crf-a-comparative-analysis-of-statistical-modeling-methods-49fc32a73586)
3. [**Another crf article**](https://medium.com/@phylypo/nlp-text-segmentation-using-conditional-random-fields-e8ff1d2b6060)
4. **Neural network CRF** [**NNCRF**](https://medium.com/@Akhilesh_k_r/neural-networks-conditional-random-field-crf-973712a0fd30)
5. [**Another one**](https://towardsdatascience.com/conditional-random-fields-explained-e5b8256da776)
6. [**scikit-learn inspired API for CRFsuite**](https://github.com/TeamHG-Memex/sklearn-crfsuite)
7. [**Sklearn wrapper**](https://github.com/supercoderhawk/sklearn-crfsuite)
8. [**Python crfsuite**](https://github.com/scrapinghub/python-crfsuite) **wrapper**
9. [**Pycrf suite vidahya**](https://www.analyticsvidhya.com/blog/2018/08/nlp-guide-conditional-random-fields-text-classification/)
### **REGRESSION ALGORITHMS**
1. [**Sk-lego**](https://scikit-lego.readthedocs.io/en/latest/preprocessing.html#Interval-Encoders) **to fit with intervals a linear regressor on top of non linear data**
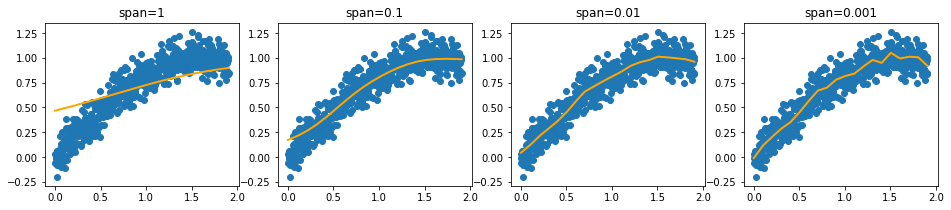
1. **Sk-lego monotonic**
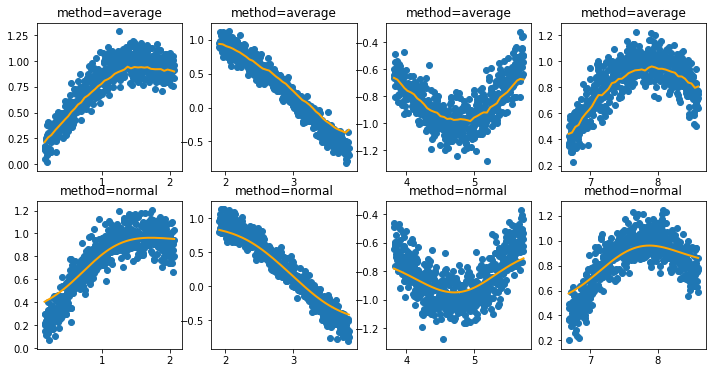
1. [**Lightning**](https://github.com/scikit-learn-contrib/lightning) **- lightning is a library for large-scale linear classification, regression and ranking in Python.**\

2. **Linear regression TBC**
3. **CART -** [**classification and regression tree**](http://www.simafore.com/blog/bid/62482/2-main-differences-between-classification-and-regression-trees)**, basically the diff between classification and regression trees - instead of IG we use sum squared error**
4. **SVR - regression based svm, with kernel only.**
5. [**NNR**](https://deeplearning4j.org/linear-regression)**- regression based NN, one output node**
6. [**LOGREG**](http://www.statisticssolutions.com/what-is-logistic-regression/) **- Logistic regression - is used as a classification algo to describe data and to explain the relationship between one dependent binary variable and one or more nominal, ordinal, interval or ratio-level independent variables. Output is BINARY. I.e., If the likelihood of killing the bug is > 0.5 it is assumed dead, if it is < 0.5 it is assumed alive.**
* **Assumes binary outcome**
* **Assumes no outliers**
* **Assumes no intercorrelations among predictors (inputs?)**
**Regression Measurements:**
1. **R^2 -** [**several reasons it can be too high.**](http://blog.minitab.com/blog/adventures-in-statistics-2/five-reasons-why-your-r-squared-can-be-too-high)
1. **Too many variables**
2. **Overfitting**
3. **Time series - seasonality trends can cause this**
2. [**RMSE vs MAE**](https://medium.com/human-in-a-machine-world/mae-and-rmse-which-metric-is-better-e60ac3bde13d)
#### **KERNEL REGRESSION**
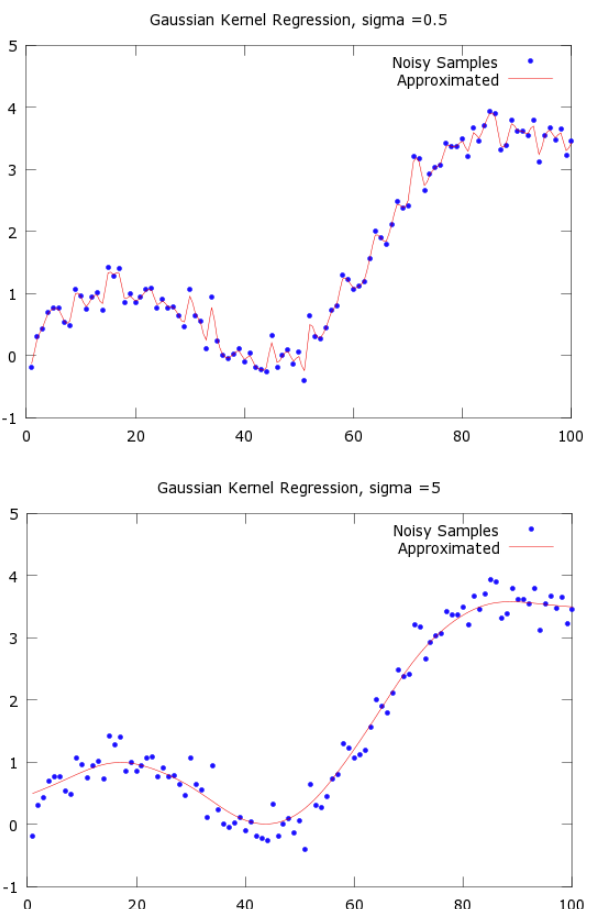
[**Gaussian Kernel Regression**](http://mccormickml.com/2014/02/26/kernel-regression/) **does–it takes a weighted average of the surrounding points**
* **variance, sigma^2. Informally, this parameter will control the smoothness of your approximated function.**
* **Smaller values of sigma will cause the function to overfit the data points, while larger values will cause it to underfit**
* **There is a proposed method to find sigma in the post!**
* **Gaussian Kernel Regression is equivalent to creating an RBF Network with the following properties: - described in the post**
### 
#### **DIMENSIONALITY REDUCTION**
**PRINCIPAL COMPONENT REGRESSION (PCR) / PARTIAL LEAST SQUARES (PLS)**
[**Principal component regression (PCR) Partial least squares and (PLS)**](https://www.kdnuggets.com/2017/11/10-statistical-techniques-data-scientists-need-master.html/2) **- basically PCA and linear regression , however PLS makes use of the response variable in order to identify the new features.**
**One can describe Principal Components Regression as an approach for deriving a low-dimensional set of features from a large set of variables. The first principal component direction of the data is along which the observations vary the most. In other words, the first PC is a line that fits as close as possible to the data. One can fit p distinct principal components. The second PC is a linear combination of the variables that is uncorrelated with the first PC, and has the largest variance subject to this constraint. The idea is that the principal components capture the most variance in the data using linear combinations of the data in subsequently orthogonal directions. In this way, we can also combine the effects of correlated variables to get more information out of the available data, whereas in regular least squares we would have to discard one of the correlated variables.**
**The PCR method that we described above involves identifying linear combinations of X that best represent the predictors. These combinations (directions) are identified in an unsupervised way, since the response Y is not used to help determine the principal component directions. That is, the response Y does not supervise the identification of the principal components, thus there is no guarantee that the directions that best explain the predictors also are the best for predicting the response (even though that is often assumed). Partial least squares (PLS) are a supervised alternative to PCR. Like PCR, PLS is a dimension reduction method, which first identifies a new smaller set of features that are linear combinations of the original features, then fits a linear model via least squares to the new M features. Yet, unlike PCR, PLS makes use of the response variable in order to identify the new features.**
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://www.mlcompendium.com/machine-learning/classic-machine-learning.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.