> For the complete documentation index, see [llms.txt](https://www.mlcompendium.com/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://www.mlcompendium.com/machine-learning/dimensionality-reduction-methods.md).
# Dimensionality Reduction Methods
* **A series on DR for dummies on medium part** [**1**](https://towardsdatascience.com/https-medium-com-abdullatif-h-dimensionality-reduction-for-dummies-part-1-a8c9ec7b7e79?_branch_match_id=584170448791192656) [**2**](https://towardsdatascience.com/dimensionality-reduction-for-dummies-part-2-3b1e3490bdc9) [**3**](https://towardsdatascience.com/dimensionality-reduction-for-dummies-part-3-f25729f74c0a)
* [**A small blog post about PCA, AE & TSNE**](https://towardsdatascience.com/reducing-dimensionality-from-dimensionality-reduction-techniques-f658aec24dfe) **in tensorflow**
* [**Visualizing PCA/TSNE using plots**](https://towardsdatascience.com/visualising-high-dimensional-datasets-using-pca-and-t-sne-in-python-8ef87e7915b)
* [**Parallex by uber for tsne \ pca visualization**](https://github.com/uber-research/parallax)
* [**About tsne / ae / pca**](https://towardsdatascience.com/reducing-dimensionality-from-dimensionality-reduction-techniques-f658aec24dfe)
* [**Does dim-reduction loses information - yes and no, in pca yes only if you use less than the entire matrix**](https://stats.stackexchange.com/questions/66060/does-dimension-reduction-always-lose-some-information)
* [**Performance comparison between dim-reduction implementations, tsne etc.**](https://umap-learn.readthedocs.io/en/latest/benchmarking.html)
###
### **TSNE**
1. [**Stat quest**](https://www.youtube.com/watch?v=NEaUSP4YerM\&list=PLblh5JKOoLUICTaGLRoHQDuF_7q2GfuJF\&index=30) **- the jist of it is that we assume a t- distribution on distances and remove those that are farther.normalized for density. T-dist used so that clusters are not clamped in the middle.**
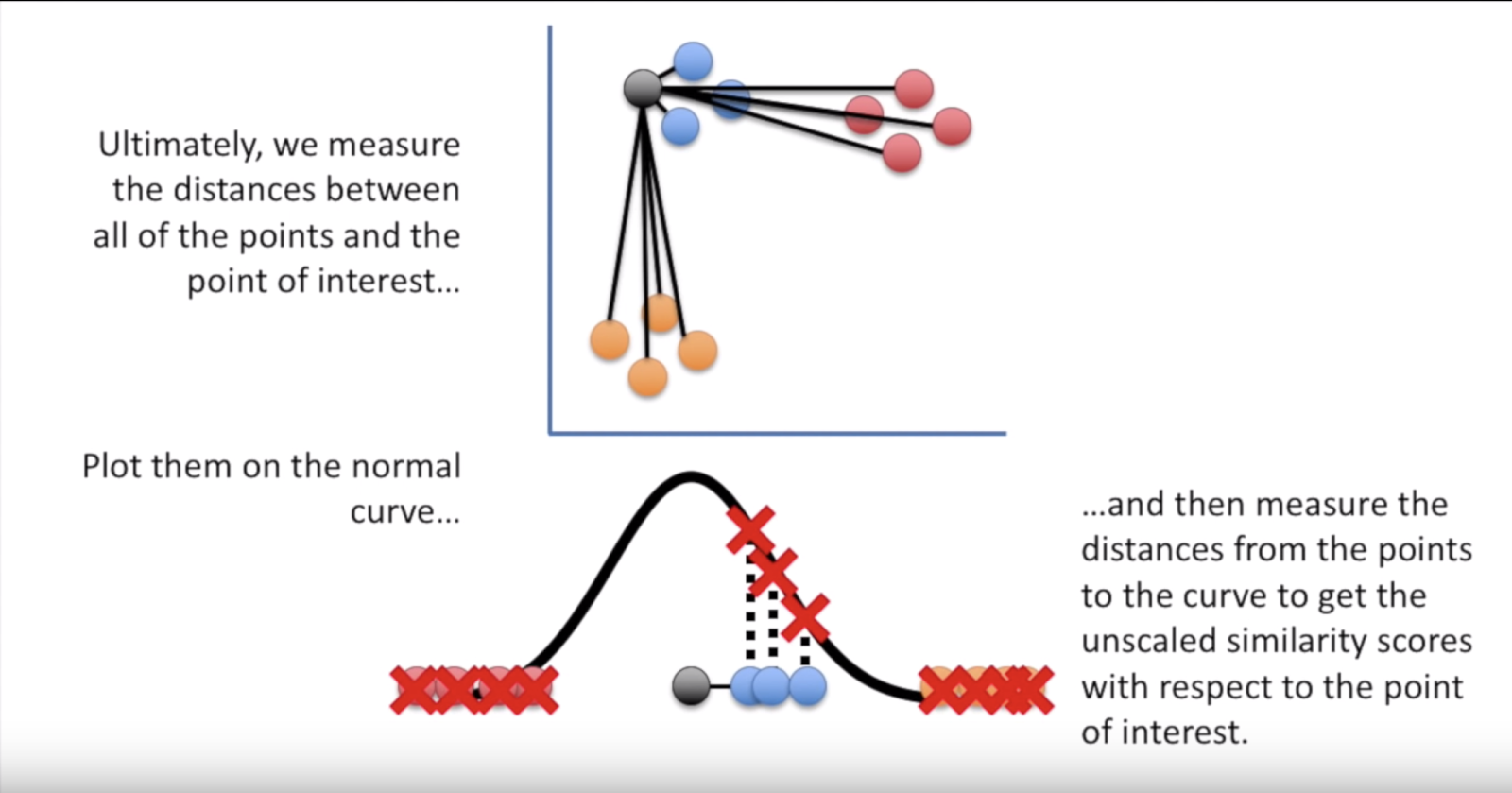
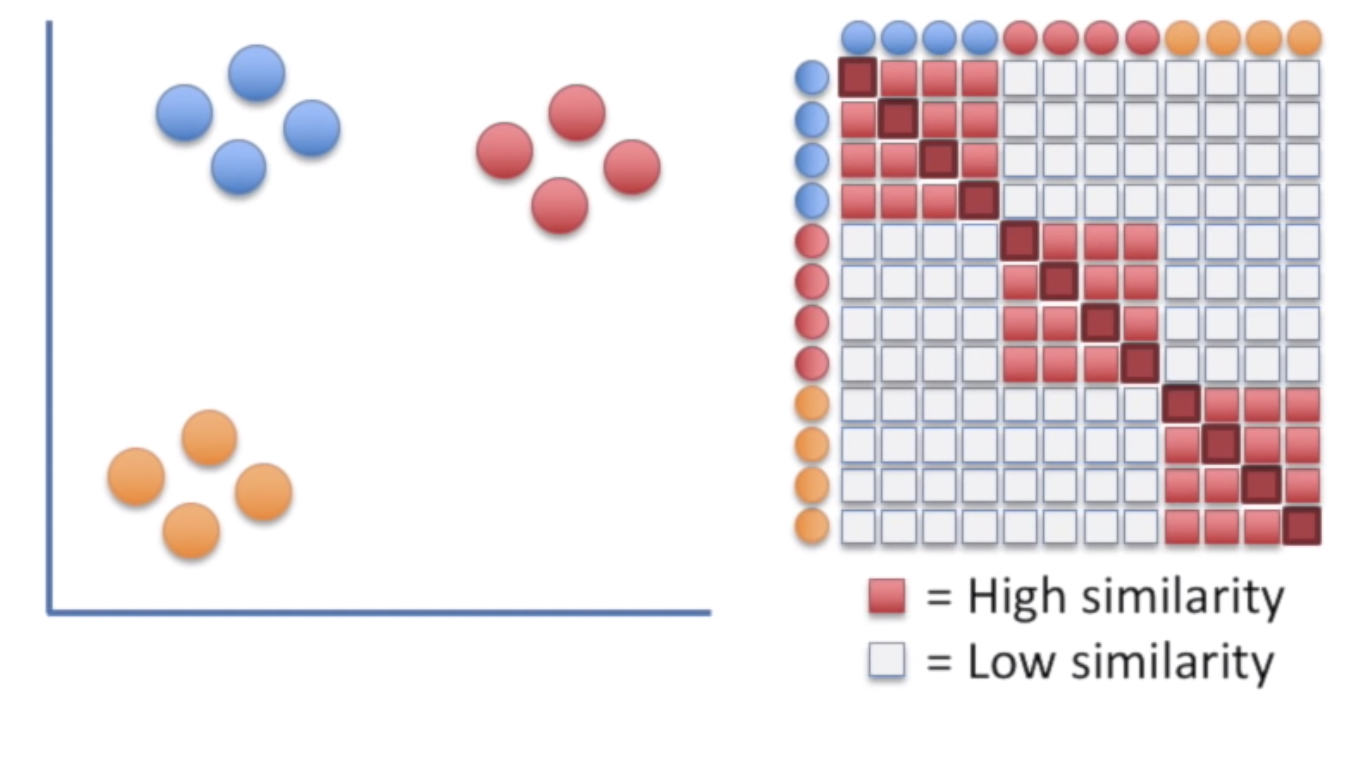
**Iteratively moving from the left to the right**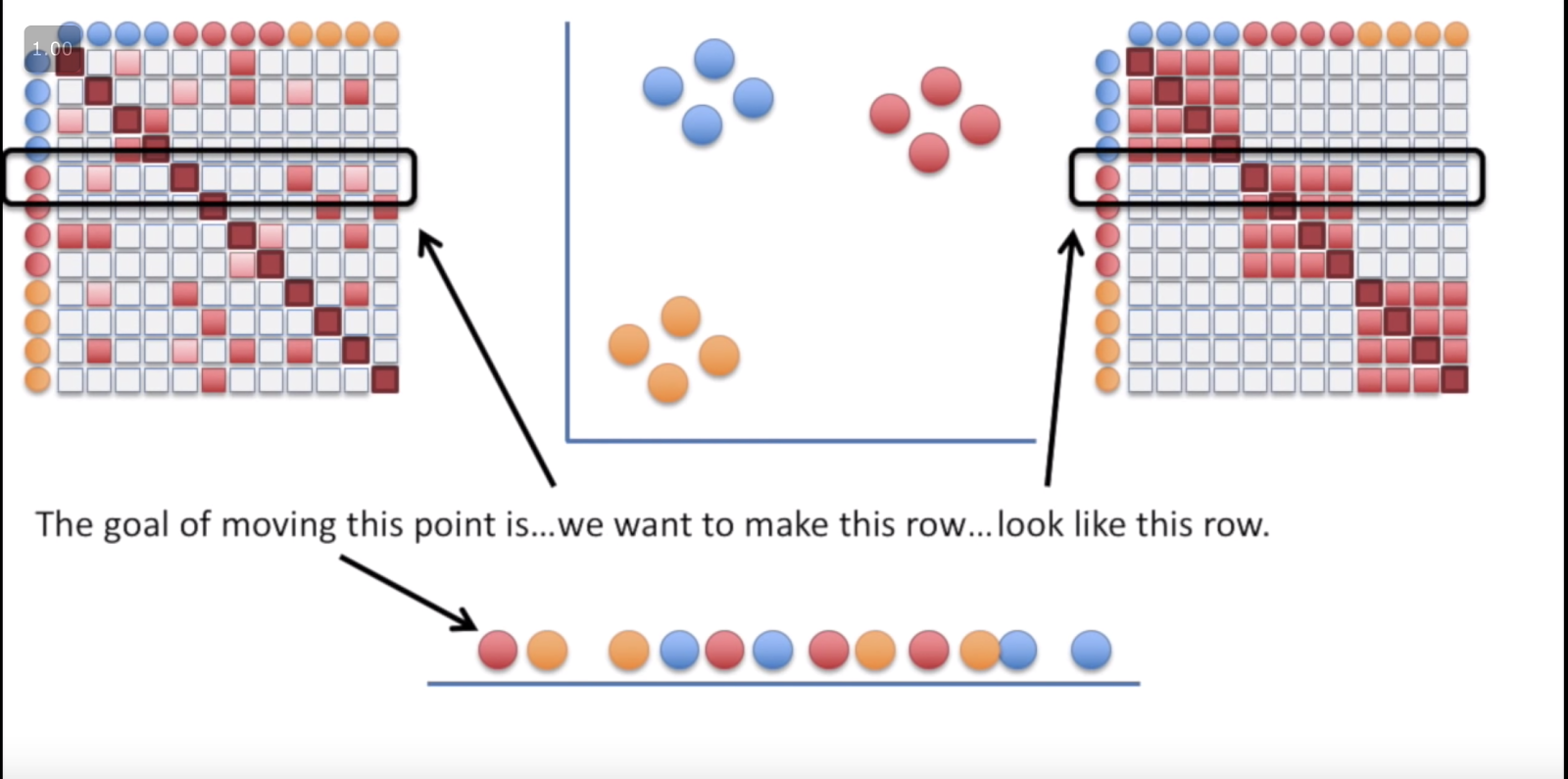
1. [**TSNE algorithm**](https://www.oreilly.com/learning/an-illustrated-introduction-to-the-t-sne-algorithm)
2. [**Are there cases where PCA more suitable than TSNE**](https://stats.stackexchange.com/questions/238538/are-there-cases-where-pca-is-more-suitable-than-t-sne?rq=1)
3. [**PCA preserving pairwise distances over tSNE?**](https://stats.stackexchange.com/questions/176672/what-is-meant-by-pca-preserving-only-large-pairwise-distances) **How why, all here.**
4. [**Another advice about using tsne and the possible misinterpetations**](https://towardsdatascience.com/why-you-are-using-t-sne-wrong-502412aab0c0)
### **PCA**
1. **Machine learning mastery:**
1. [**Expected value, variance, covariance** ](https://machinelearningmastery.com/introduction-to-expected-value-variance-and-covariance)
2. [**PCA**](https://machinelearningmastery.com/calculate-principal-component-analysis-scratch-python/) **(remove the mean from A, calculate cov(A), calculate eig(cov), A\*eigK = PCA)**
3. [**EigenDecomposition**](https://machinelearningmastery.com/introduction-to-eigendecomposition-eigenvalues-and-eigenvectors/) **- what is an eigen vector - simply put its a vector that satisfies A\*v = lambda\*v, how to use eig() and how to confirm an eigenvector/eigenvalue and reconstruct the original A matrix.**
4. [**SVD**](https://machinelearningmastery.com/singular-value-decomposition-for-machine-learning)
5. **What is missing is how the EigenDecomposition is calculated.**
2. [**PCA on large matrices!**](https://amedee.me/post/pca-large-matrices/)
1. **Randomized svd**
2. **Incremental svd**
3. [**PCA on Iris**](http://sebastianraschka.com/Articles/2015_pca_in_3_steps.html)
4. **(did not read)** [**What is PCA?**](https://stats.stackexchange.com/questions/222/what-are-principal-component-scores)
5. **(did not read)** [**What is a covariance matrix?**](https://en.wikipedia.org/wiki/Covariance_matrix)
6. **(did not read)** [**Variance covariance matrix**](http://stattrek.com/matrix-algebra/covariance-matrix.aspx)
7. [**Visualization of the first PCA vectors**](https://medium.com/@rtjeannier/using-pca-to-visualize-high-dimensional-data-6ff028c911c5)**, it is unclear what he is trying to show.**
8. [**A very nice introductory tutorial on how to use PCA**](https://www.analyticsvidhya.com/blog/2016/03/practical-guide-principal-component-analysis-python/)
9. **\*\*** [**An in-depth tutorial on PCA (paper)**](https://www.cs.princeton.edu/picasso/mats/PCA-Tutorial-Intuition_jp.pdf)
10. **\*\*** [**yet another tutorial paper on PCA (looks good)**](https://www.researchgate.net/publication/309165405_Principal_component_analysis_-_a_tutorial)
11. [**How to use PCA in Cross validation and for train\test split**](https://stats.stackexchange.com/questions/114560/pca-on-train-and-test-datasets-do-i-need-to-merge-them)**. (bottom line, do it on the train only.)**
12. [**Another tutorial paper - looks decent**](https://www.researchgate.net/publication/309165405_Principal_component_analysis_-_a_tutorial)
13. [**PCA whitening**](http://mccormickml.com/2014/06/03/deep-learning-tutorial-pca-and-whitening/)**,** [**Stanford tutorial**](http://ufldl.stanford.edu/tutorial/unsupervised/PCAWhitening/) **(pca/zca whitening),** [**Stackoverflow (really good)**](https://stats.stackexchange.com/questions/117427/what-is-the-difference-between-zca-whitening-and-pca-whitening/117459) **,**
**There are two things we are trying to accomplish with whitening:**
1. **Make the features less correlated with one another.**
2. **Give all of the features the same variance.**
**Whitening has two simple steps:**
1. **Project the dataset onto the eigenvectors. This rotates the dataset so that there is no correlation between the components.**
2. **Normalize the the dataset to have a variance of 1 for all components. This is done by simply dividing each component by the square root of its eigenvalue.**
### **SVD**
1. [**An explanation about SVD’s formulas.**](https://blog.statsbot.co/singular-value-decomposition-tutorial-52c695315254)
### **KPCA**
1. [**First they say that**](https://web.cs.hacettepe.edu.tr/~aykut/classes/fall2016/bbm406/slides/l25-kernel_pca.pdf) **Autoencoder is PCA based on their equation, i.e. minimize the reconstruction error formula.**
2. **Then they say that PCA cant separate certain non-linear situations (circle within a circle), therefore they introduce kernel based PCA (using the kernel trick - like svm) which mapps the space to another linearly separable space, and performs PCA on it,**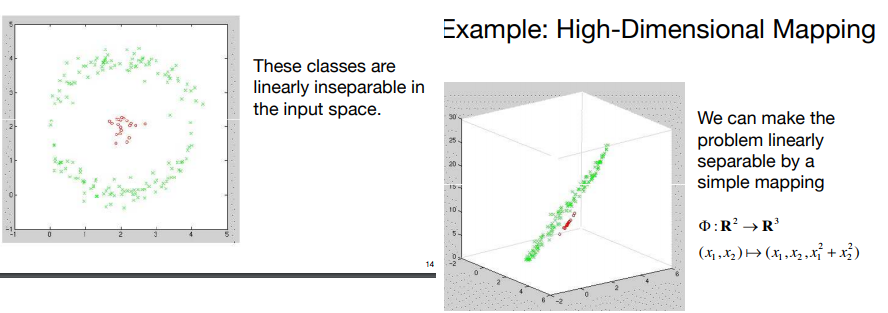
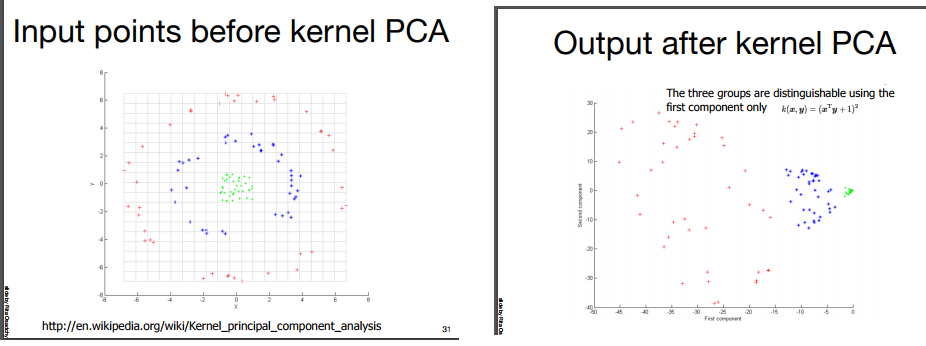
1. **Finally, showing results how KPCA works well on noisy images, compared to PCA.**

### **LDA - Linear discriminant analysis**
[**A comparison / tutorial with code on pca vs lda - read!**](http://rstudio-pubs-static.s3.amazonaws.com/84669_cd15214061d44e1493ffee69c5d55925.html)
[**A comprehensive tutorial on LDA - read!**](https://iksinc.online/2018/11/12/dimensionality-reduction-via-linear-discriminant-analysis/?fbclid=IwAR3d0ja_HP0DkamiL3W4QxzjcsIfoySB_G7LetTNf0cE0ed_MVduXfi6bv0)
[**Dim reduction with LDA - nice examples**](https://iksinc.online/2018/11/12/dimensionality-reduction-via-linear-discriminant-analysis/?fbclid=IwAR3d0ja_HP0DkamiL3W4QxzjcsIfoySB_G7LetTNf0cE0ed_MVduXfi6bv0)
**(**[**Not to be confused with the other LDA**](http://sebastianraschka.com/Articles/2014_python_lda.html)**) - Linear Discriminant Analysis (LDA) is most commonly used as dimensionality reduction technique in the pre-processing step for pattern-classification and machine learning applications. The goal is to project a dataset onto a lower-dimensional space with good class-separability in order avoid overfitting (“curse of dimensionality”) and also reduce computational costs.**
**PCA vs LDA:**
**Both Linear Discriminant Analysis (LDA) and Principal Component Analysis (PCA) are linear transformation techniques used for dimensionality reduction.**
* **PCA can be described as an “unsupervised” algorithm, since it “ignores” class labels and its goal is to find the directions (the so-called principal components) that maximize the variance in a dataset.**
* **In contrast to PCA, LDA is “supervised” and computes the directions (“linear discriminants”) that will represent the axes that maximize the separation between multiple classes.**
**Although it might sound intuitive that LDA is superior to PCA for a multi-class classification task where the class labels are known, this might not always the case.**
**For example, comparisons between classification accuracies for image recognition after using PCA or LDA show that :**
* **PCA tends to outperform LDA if the number of samples per class is relatively small (**[**PCA vs. LDA**](http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=908974)**, A.M. Martinez et al., 2001).**
* **In practice, it is also not uncommon to use both LDA and PCA in combination:**
**Best Practice: PCA for dimensionality reduction can be followed by an LDA. But before we skip to the results of the respective linear transformations, let us quickly recapitulate the purposes of PCA and LDA: PCA finds the axes with maximum variance for the whole data set where LDA tries to find the axes for best class separability. In practice, often a LDA is done followed by a PCA for dimensionality reduction.**
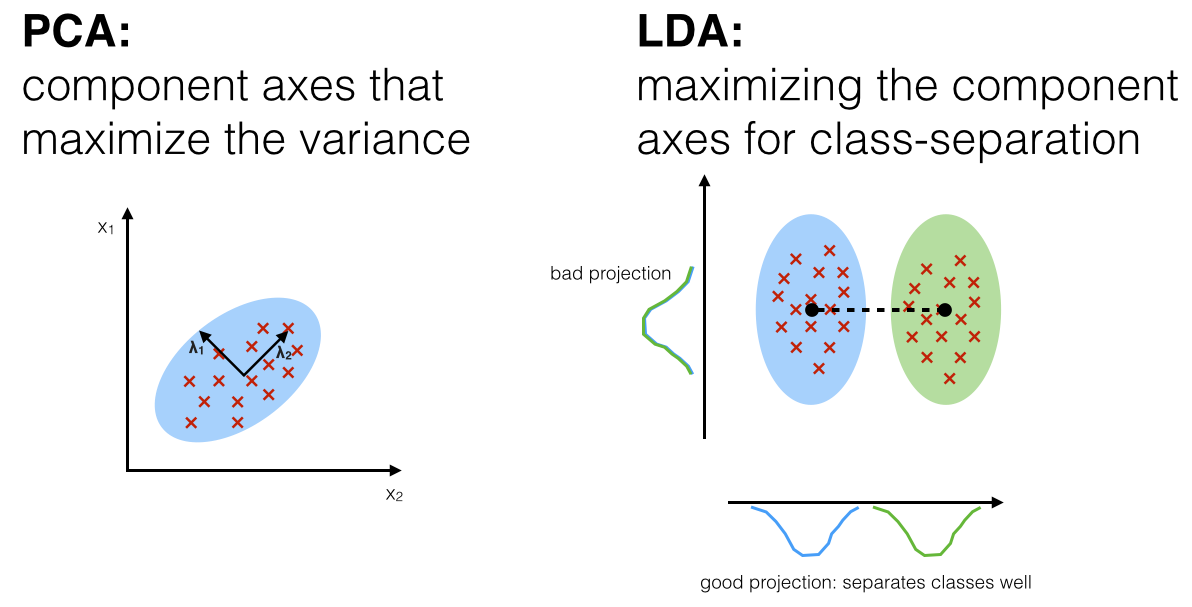
**\*\* To fully understand the details please follow the LDA link to the original and very informative article**
**\*\*\* TODO: need some benchmarking for PCA\LDA\LSA\ETC..**
###
### **KDA - KERNEL DISCRIMINANT ANALYSIS**
1. [**pyDML package**](https://pydml.readthedocs.io/en/latest/dml.html#dml.kda.KDA) **- has KDA - This package provides the classic algorithms of supervised distance metric learning, together with some of the newest proposals.**

### **LSA**
[**LSA**](http://mccormickml.com/2016/03/25/lsa-for-text-classification-tutorial/) **is quite simple, you just use SVD to perform dimensionality reduction on the tf-idf vectors–that’s really all there is to it! And** [**LSA CLUSTERING**](http://mccormickml.com/2015/08/05/document-clustering-example-in-scikit-learn/)
**Here is a very nice** [**tutorial about LSA,**](https://technowiki.wordpress.com/2011/08/27/latent-semantic-analysis-lsa-tutorial/) **with code, explaining what are the three matrices, word clustering, sentence clustering and vector importance. They say that for sentence space we need to remove the first vector as it is correlated with sentence length.**
**\*how to** [**interpret LSA vectors**](http://mccormickml.com/2016/03/25/lsa-for-text-classification-tutorial/)
**PCA vs LSA: (**[**intuition1**](https://stats.stackexchange.com/questions/65699/lsa-vs-pca-document-clustering)**,** [**intuition2**](https://math.stackexchange.com/questions/3869/what-is-the-intuitive-relationship-between-svd-and-pca)**)**
* **reduction of the dimensionality**
* **noise reduction**
* **incorporating relations between terms into the representation.**
* **SVD and PCA and "total least-squares" (and several other names) are the same thing. It computes the orthogonal transform that decorrelates the variables and keeps the ones with the largest variance. There are two numerical approaches: one by SVD of the (centered) data matrix, and one by Eigen decomposition of this matrix "squared" (covariance).**
[**LSA vs W2V**](https://arxiv.org/pdf/1610.01520.pdf)
### **ICA**
1. **While PCA is global, it finds global variables (with images we get eigen faces, good for reconstruction) that maximizes variance in orthogonal directions, and is not influenced by the TRANSPOSE of the data matrix.**
2. **On the other hand, ICA is local and finds local variables (with images we get eyes ears, mouth, basically edges!, etc), ICA will result differently on TRANSPOSED matrices, unlike PCA, its also “directional” - consider the “cocktail party” problem. On documents, ICA gives topics.**
3. **It helps, similarly to PCA, to help us analyze our data.**
**Sparse** [**info on ICA with security returns.**](https://www.quantopian.com/posts/an-experiment-with-independent-component-analysis)
### **MANIFOLD**
1. [**The best tutorial that explains manifold (high to low dim projection/mapping/visuzation)**](https://jhui.github.io/2017/01/15/Machine-learning-Multi-dimensional-scaling-and-visualization/) **(pca, sammon, isomap, tsne)**
2. [**Many manifold methods used to visualize high dimensional data.** ](http://scikit-learn.org/stable/modules/manifold.html#t-sne)
3. [**Comparing manifold methods**](http://scikit-learn.org/stable/auto_examples/manifold/plot_compare_methods.html#sphx-glr-auto-examples-manifold-plot-compare-methods-py)
#### **T-SNE**
1. [**Code and in-depth tutorial on TSNE, mapping probabilities to distributions**](https://towardsdatascience.com/t-sne-python-example-1ded9953f26)**\*\*\*\***
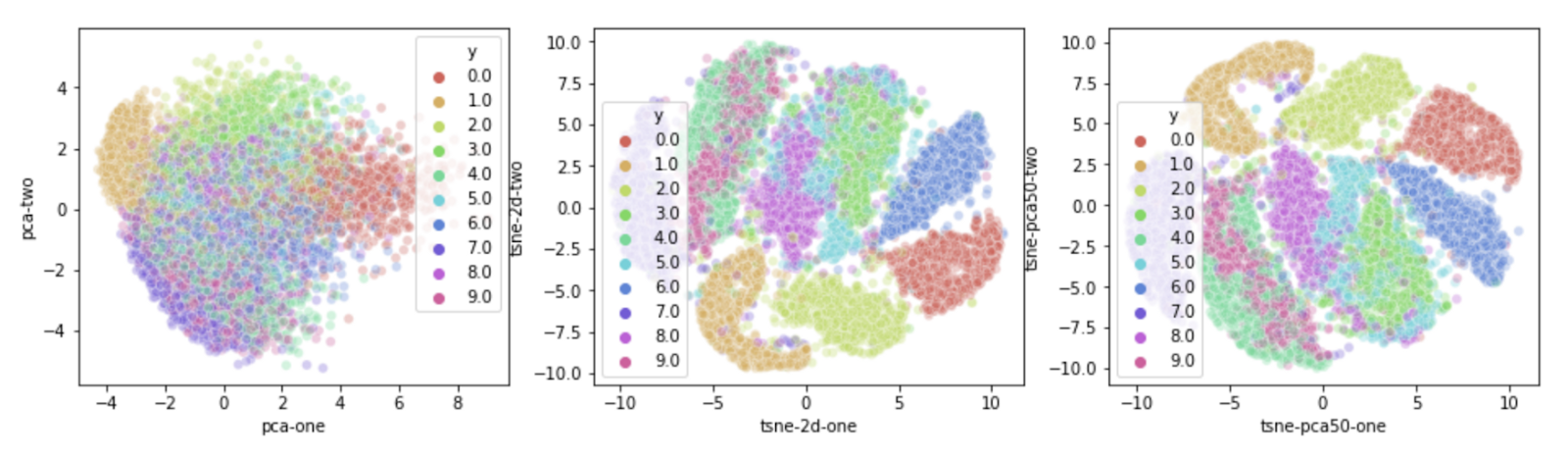
2. [**A great example of using PCA and then TSNE to see clusters that arent visible with PCA only.**](https://towardsdatascience.com/dimensionality-reduction-by-stacking-pca-and-t-sne-420d9fcfab54)
3. [**Misreading T-SNE**](https://distill.pub/2016/misread-tsne/)**, this is a very important read.**
4. **In contrary to what it says on sklearn’s website, TSNE is not suited ONLY for visualization, you** [**can also use it for data reduction**](https://lvdmaaten.github.io/tsne/)
5. **“t-Distributed Stochastic Neighbor Embedding (t-SNE) is a (**[**prize-winning**](http://blog.kaggle.com/2012/11/02/t-distributed-stochastic-neighbor-embedding-wins-merck-viz-challenge/)**) technique for dimensionality reduction that is particularly well suited for the visualization of high-dimensional datasets.”**
6. [**Comparing PCA and TSNE, then pushing PCA to TSNE and seeing what happens (as recommended in SKLEARN**](https://medium.com/@luckylwk/visualising-high-dimensional-datasets-using-pca-and-t-sne-in-python-8ef87e7915b)
7. [**TSNE + AUTOENCODER example**](https://towardsdatascience.com/reducing-dimensionality-from-dimensionality-reduction-techniques-f658aec24dfe)
#### **Sammons embedding mapping**
1. [**In tensorflow**](https://datawarrior.wordpress.com/2017/06/01/sammon-embedding-with-tensorflow/)
#### **IVIS**
1. [**Paper:** ](https://www.nature.com/articles/s41598-019-45301-0)
2. [**Git**](https://github.com/beringresearch/ivis)**,** [**docs**](https://bering-ivis.readthedocs.io/en/latest/)
3. [**Ivis animate**](https://github.com/beringresearch/ivis-animate)
4. [**Ivis explain**](https://github.com/beringresearch/ivis-explain)
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter, and the optional `goal` query parameter:
```
GET https://www.mlcompendium.com/machine-learning/dimensionality-reduction-methods.md?ask=&goal=
```
`ask` is the immediate question: it should be specific, self-contained, and written in natural language.
`goal` is optional and describes the broader end goal you are ultimately trying to accomplish on behalf of the user. GitBook uses it to tailor the answer towards what is most useful for that goal.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.