> For the complete documentation index, see [llms.txt](https://www.mlcompendium.com/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://www.mlcompendium.com/machine-learning/anomaly-detection.md).
# Anomaly Detection
**“whether a new observation belongs to the same distribution as existing observations (it is an inlier), or should be considered as different (it is an outlier).**
**=> Often, this ability is used to clean real data sets**
**Two important distinctions must be made:**
| **novelty detection:** | |
| ---------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| | **The training data is not polluted by outliers, and we are interested in detecting anomalies in new observations.** |
| **outlier detection:** | |
| | The training data contains outliers, and we need to fit the central mode of the training data, ignoring the deviant observations
|
1. [Using IQR for AD and why IQR difference is 2.7 sigma](https://towardsdatascience.com/why-1-5-in-iqr-method-of-outlier-detection-5d07fdc82097)
2. [**Medium**](https://towardsdatascience.com/anomaly-detection-for-dummies-15f148e559c1#:~:text=K%20%2D%20Nearest%20Neighbors%20\(KNN\),algorithms%20were%20not%20very%20different.) **- good**
3. [**kdnuggets**](https://www.kdnuggets.com/2017/04/datascience-introduction-anomaly-detection.html)
4. **Index for** [**Z-score and other moving averages.** ](https://turi.com/learn/userguide/anomaly_detection/moving_zscore.html)
5. [**A survey**](https://d1wqtxts1xzle7.cloudfront.net/49916547/Mohiuddin_Survey_financial_2015.pdf?1477591055=\&response-content-disposition=inline%3B+filename%3DA_survey_of_anomaly_detection_techniques.pdf\&Expires=1594649751\&Signature=U~N32meGWYyIIQz1zRYC4s2tCb7e5ut28GIBC3GSG4250UjhgTMQwEIB63zwPKtS5JyKew7RWVog8gytIhc3GSSfTwsRM7lqyghuDgbds-QMp3mNyVw2bYNztnoOWncHG8rhtkwUK1EbWcYeLKvqARnJoAS177C8r1GAhfKp14GgJzHpmnsoSkB6AowJ68nauf2VyA1b~w1m~UfSNoWtjbL59clAqHn7nfqw5PGBuLHSSSxCa5PX09mADy4VzuOySzYjIviRwOlgT1eQrART0KqozqVSiGKM3SeapuI3K5tSERVPPSTnpupp--WJyYCNzzvPrdjB121P2XU7fq73wQ__\&Key-Pair-Id=APKAJLOHF5GGSLRBV4ZA)
6. [**A great tutorial**](https://www.analyticsvidhya.com/blog/2019/02/outlier-detection-python-pyod/?utm_source=facebook.com\&utm_medium=social\&fbclid=IwAR33KDnGMf5zp491WmhTsCFtinBDUp5RaVnoC4Cfxcc5rfo2yHreMo3M_M4) **about AD using 20 algos in a** [**single python package**](https://github.com/yzhao062/pyod)**.**
7. [**Mastery on classifying rare events using lstm-autoencoder**](https://machinelearningmastery.com/lstm-model-architecture-for-rare-event-time-series-forecasting/)
8. **A** [**comparison**](http://scikit-learn.org/stable/modules/outlier_detection.html#outlier-detection) **of One-class SVM versus Elliptic Envelope versus Isolation Forest versus LOF in sklearn. (The examples below illustrate how the performance of the** [**covariance.EllipticEnvelope**](http://scikit-learn.org/stable/modules/generated/sklearn.covariance.EllipticEnvelope.html#sklearn.covariance.EllipticEnvelope) **degrades as the data is less and less unimodal. The** [**svm.OneClassSVM**](http://scikit-learn.org/stable/modules/generated/sklearn.svm.OneClassSVM.html#sklearn.svm.OneClassSVM) **works better on data with multiple modes and** [**ensemble.IsolationForest**](http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.html#sklearn.ensemble.IsolationForest) **and**[**neighbors.LocalOutlierFactor**](http://scikit-learn.org/stable/modules/generated/sklearn.neighbors.LocalOutlierFactor.html#sklearn.neighbors.LocalOutlierFactor) **perform well in every cases.)**
9. [**Using Autoencoders**](https://shiring.github.io/machine_learning/2017/05/01/fraud) **- the information is there, but its all over the place.**
10. **Twitter anomaly -**
11. **Microsoft anomaly - a well documented black box, i cant find a description of the algorithm, just hints to what they sort of did**
1. [**up/down trend, dynamic range, tips and dips**](https://blogs.technet.microsoft.com/machinelearning/2014/11/05/anomaly-detection-using-machine-learning-to-detect-abnormalities-in-time-series-data/)
2. [**Api here**](https://docs.microsoft.com/en-us/azure/machine-learning/team-data-science-process/apps-anomaly-detection-api)
12. **STL and** [**LSTM for anomaly prediction**](https://github.com/omri374/moda/blob/master/moda/example/lstm/LSTM_AD.ipynb) **by microsoft**
1. [**Medium on AD**](https://towardsdatascience.com/machine-learning-for-anomaly-detection-and-condition-monitoring-d4614e7de770)
2. [**Medium on AD using mahalanobis, AE and**](https://towardsdatascience.com/how-to-use-machine-learning-for-anomaly-detection-and-condition-monitoring-6742f82900d7)
### **OUTLIER DETECTION**
1. [**Alibi Detect**](https://github.com/SeldonIO/alibi-detect) **is an open source Python library focused on outlier, adversarial and drift detection. The package aims to cover both online and offline detectors for tabular data, text, images and time series. The outlier detection methods should allow the user to identify global, contextual and collective outliers.**\
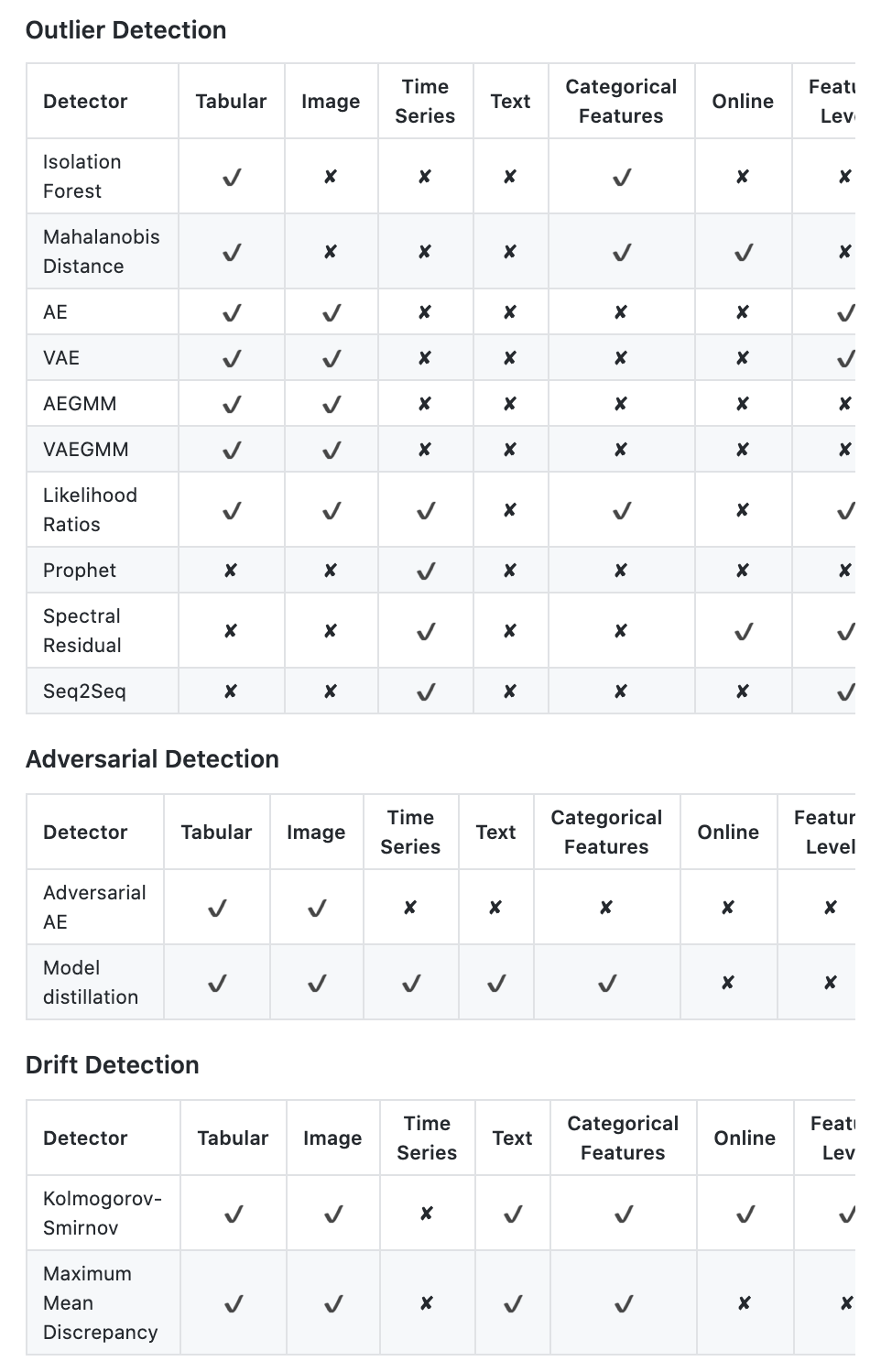\
2. [**Pyod**](https://pyod.readthedocs.io/en/latest/pyod.html)


1. [**Anomaly detection resources**](https://github.com/yzhao062/anomaly-detection-resources) **(great)**
2. [**Novelty and outlier detection inm sklearn**](https://scikit-learn.org/stable/modules/outlier_detection.html)
3. [**SUOD**](https://github.com/yzhao062/suod) **(Scalable Unsupervised Outlier Detection) is an acceleration framework for large-scale unsupervised outlier detector training and prediction. Notably, anomaly detection is often formulated as an unsupervised problem since the ground truth is expensive to acquire. To compensate for the unstable nature of unsupervised algorithms, practitioners often build a large number of models for further combination and analysis, e.g., taking the average or majority vote. However, this poses scalability challenges in high-dimensional, large datasets, especially for proximity-base models operating in Euclidean space.**
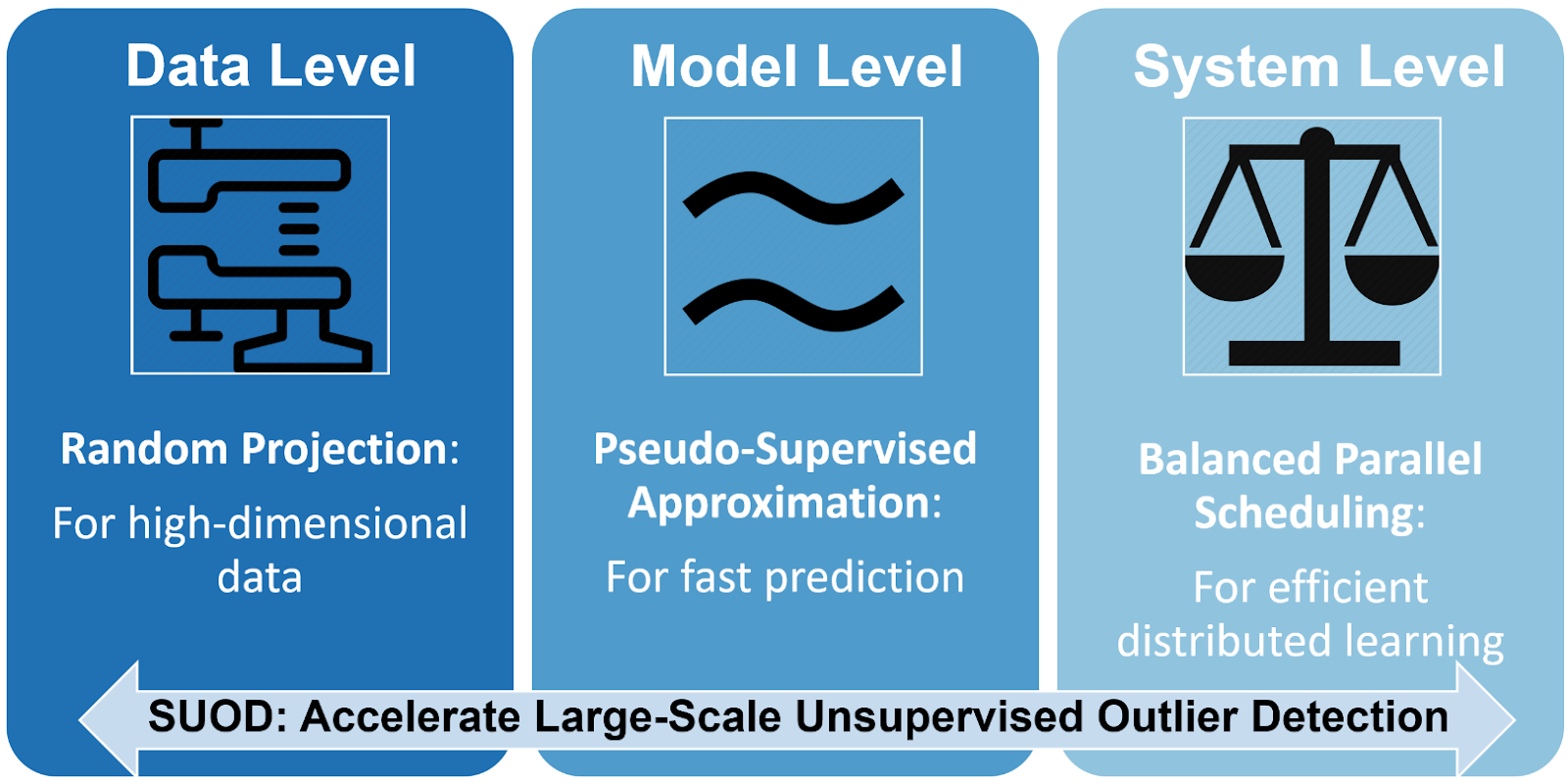
**SUOD is therefore proposed to address the challenge at three complementary levels: random projection (data level), pseudo-supervised approximation (model level), and balanced parallel scheduling (system level). As mentioned, the key focus is to accelerate the training and prediction when a large number of anomaly detectors are presented, while preserving the prediction capacity. Since its inception in Jan 2019, SUOD has been successfully used in various academic researches and industry applications, include PyOD** [**\[2\]**](https://github.com/yzhao062/suod#zhao2019pyod) **and** [**IQVIA**](https://www.iqvia.com/) **medical claim analysis. It could be especially useful for outlier ensembles that rely on a large number of base estimators.**
1. [**Skyline**](https://github.com/earthgecko/skyline)
2. [**Scikit-lego**](https://scikit-lego.readthedocs.io/en/latest/outliers.html)
1. 
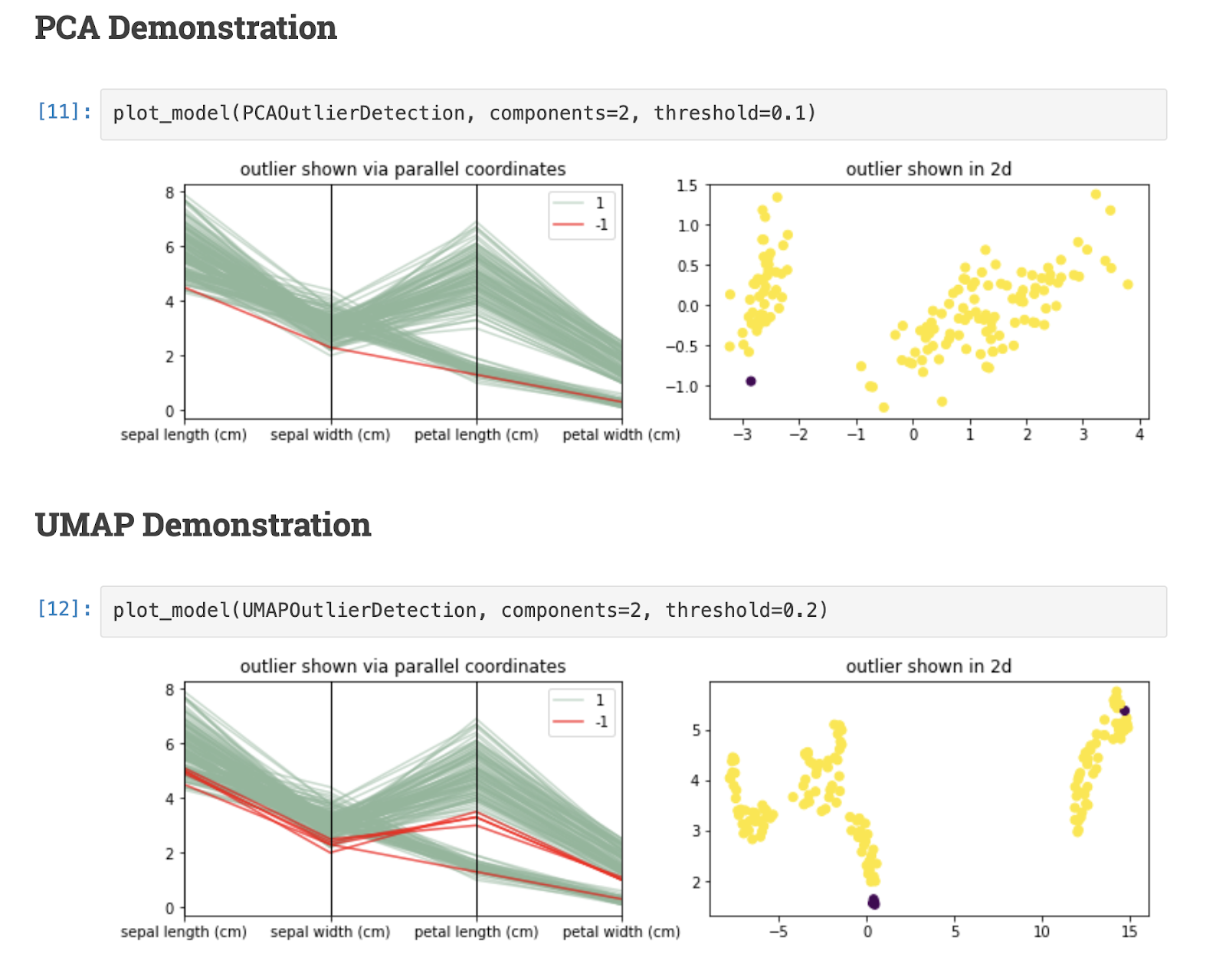
2. 

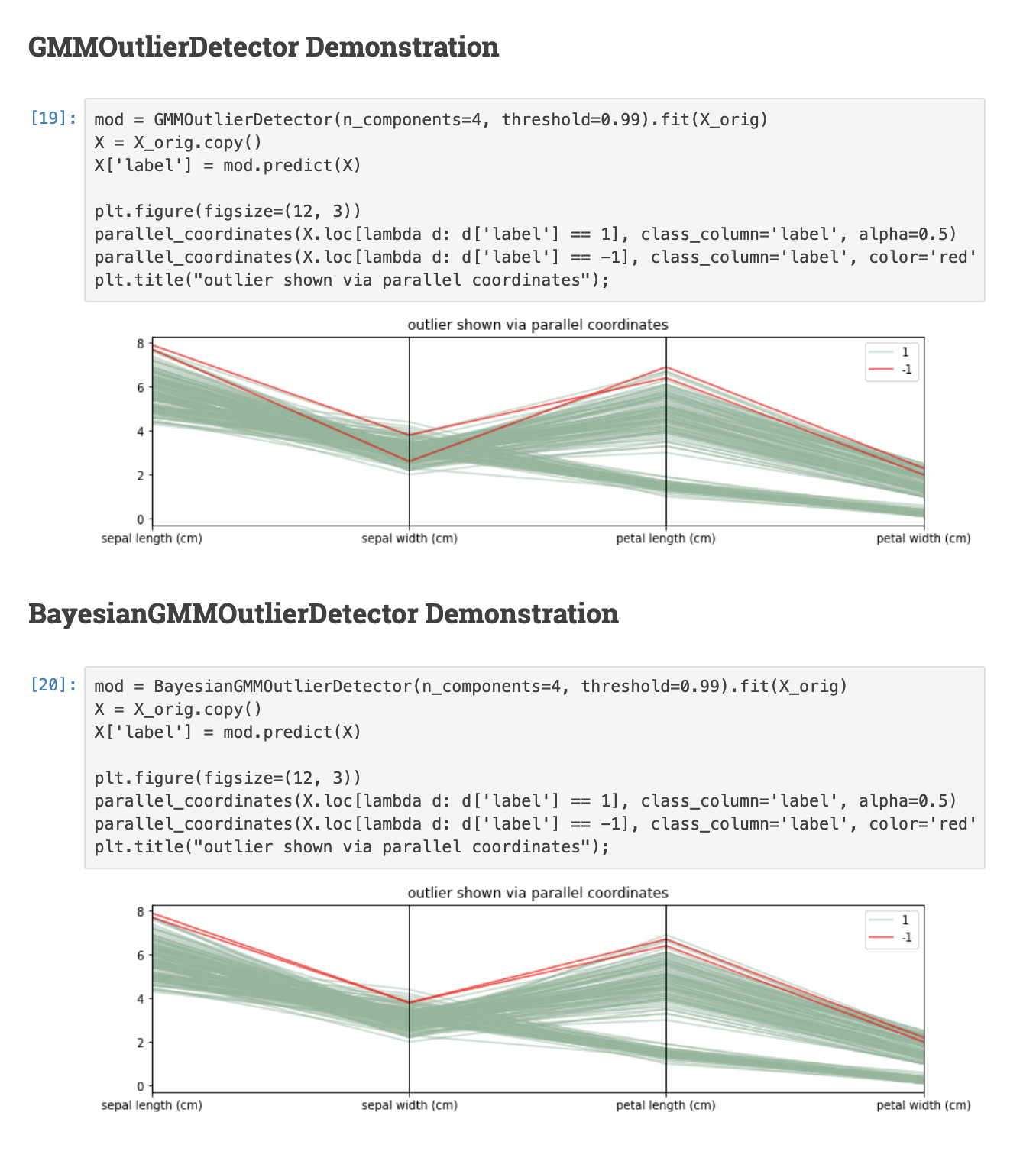
1. 
###
### **ISOLATION FOREST**
[**The best resource to explain isolation forest**](http://blog.easysol.net/using-isolation-forests-anamoly-detection/) **- the basic idea is that for an anomaly (in the example) only 4 partitions are needed, for a regular point in the middle of a distribution, you need many many more.**
[**Isolation Forest**](http://scikit-learn.org/stable/auto_examples/ensemble/plot_isolation_forest.html) **-Isolating observations:**
* **randomly selecting a feature**
* **randomly selecting a split value between the maximum and minimum values of the selected feature.**
**Recursive partitioning can be represented by a tree structure, the number of splittings required to isolate a sample is equivalent to the path length from the root node to the terminating node.**
**This path length, averaged over a forest of such random trees, is a measure of normality and our decision function.**
**Random partitioning produces noticeable shorter paths for anomalies.**
**=> when a forest of random trees collectively produce shorter path lengths for particular samples, they are highly likely to be anomalies.**
[**the paper is pretty good too -**](https://cs.nju.edu.cn/zhouzh/zhouzh.files/publication/icdm08b.pdf) **In the training stage, iTrees are constructed by recursively partitioning the given training set until instances are isolated or a specific tree height is reached of which results a partial model.**
**Note that the tree height limit l is automatically set by the sub-sampling size ψ: l = ceiling(log2 ψ), which is approximately the average tree height \[7].**
**The rationale of growing trees up to the average tree height is that we are only interested in data points that have shorter-than average path lengths, as those points are more likely to be anomalies**\
### **LOCAL OUTLIER FACTOR**
* [**LOF**](http://scikit-learn.org/stable/modules/outlier_detection.html#local-outlier-factor) **computes a score (called local outlier factor) reflecting the degree of abnormality of the observations.**
* **It measures the local density deviation of a given data point with respect to its neighbors. The idea is to detect the samples that have a substantially lower density than their neighbors.**
* **In practice the local density is obtained from the k-nearest neighbors.**
* **The LOF score of an observation is equal to the ratio of the average local density of his k-nearest neighbors, and its own local density:**
* **a normal instance is expected to have a local density similar to that of its neighbors,**
* **while abnormal data are expected to have much smaller local density.**
### **ELLIPTIC ENVELOPE**
1. **We assume that the regular data come from a known distribution (e.g. data are Gaussian distributed).**
2. **From this assumption, we generally try to define the “shape” of the data,**
3. **And can define outlying observations as observations which stand far enough from the fit shape.**
### **ONE CLASS SVM**
1. [**A nice article about ocs, with github code, two methods are described.**](http://rvlasveld.github.io/blog/2013/07/12/introduction-to-one-class-support-vector-machines/)
2. [**Resources for ocsvm**](https://www.quora.com/What-is-a-good-resource-for-understanding-One-Class-SVM-for-distribution-esitmation)
3. **It looks like there are** [**two such methods**](http://rvlasveld.github.io/blog/2013/07/12/introduction-to-one-class-support-vector-machines/)**, - The 2nd one: The algorithm obtains a spherical boundary, in feature space, around the data. The volume of this hypersphere is minimized, to minimize the effect of incorporating outliers in the solution.**
**The resulting hypersphere is characterized by a center and a radius R>0 as distance from the center to (any support vector on) the boundary, of which the volume R2 will be minimized.**\
### **CLUSTERING METRICS**
**For community detection, text clusters, etc.**
[**Google search for convenience**](https://www.google.com/search?biw=1600\&bih=912\&sxsrf=ALeKk00NbB52pfM6J1N42ieEddIOirBmcQ%3A1597514997743\&ei=9SQ4X-_uLLLhkgWJsIbADw\&q=word+embedding+silhouette+score\&oq=word+embedding+silhouette+score\&gs_lcp=CgZwc3ktYWIQAzoECAAQRzoECCMQJzoHCCMQsAIQJ1DVd1jqjQFgm5ABaARwAXgBgAGMAogBrQ2SAQUwLjkuMpgBAKABAaoBB2d3cy13aXrAAQE\&sclient=psy-ab\&ved=0ahUKEwivvdqP553rAhWysKQKHQmYAfg4ChDh1QMIDA\&uact=5)
**Silhouette:**
1. [**TFIDF, PCA, SILHOUETTE**](https://towardsdatascience.com/mmmm-foodporn-a-clustering-and-classification-study-using-natural-language-processing-e2eae8ddefe1) **for deciding how many clusters to use, the knee/elbow method.**
2. [**Embedding based silhouette community detection**](https://link.springer.com/article/10.1007/s10994-020-05882-8#Sec10)
3. [**A notebook**](https://rlbarter.github.io/superheat-examples/word2vec/)**, using the SuperHeat package, clustering w2v cosine similarity matrix, measuring using silhouette score.**
4. [**Topic modelling clustering, cant access this document on github**](https://github.com/danielwilentz/Cuisine-Classifier/blob/master/topic_modeling/clustering.ipynb)
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://www.mlcompendium.com/machine-learning/anomaly-detection.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.